2023-HGU-ML Lecture 5. Density Estimation
Density Estimation
- for a data sample, we need a vector to represent
- for a dataset with many samples, we need the distribution of the samples to understand the dataset
- Density Estimation
- estimation of an underlying probability density function p(x) based on observed data
- we can understand the population (unsupervised)
- the density can be used for classification
- parametric methods
- assuming a functional form about the distribution (e.g., Gaussian)
- estimating the parameters (e.g., mean and variance)
- non-parametric methods
- no assumption on the distribution
- estimating the density directly from data
- semi-parametric methods
- a very general class of functional forms
- with more parameters than parametric methods
- estimation theory
- estimating the unknown parameters from data
- bias
- error from assumptions in the learning algorithm
- underfitting
- variance
- error from sensitivity to small fluctuations in the data
- overfitting
- bias-variance trade-off
- maximum likelihood estimation (MLE)
- a method of estimating the parameters of a distribution
- by maximizing a likelihood function
- the observed data will be most probable
- maximum likelihood estimate
- estimated parameter maximizing the likelihood function
- https://angeloyeo.github.io/2020/07/17/MLE.html
- a method of estimating the parameters of a distribution
- likelihood of Gaussian distribution
- how likely is the data to occur given the parameters
- log-likelihood
- the log function is monotonic and makes the likelihood equation much simpler
-
MLE for Gaussian

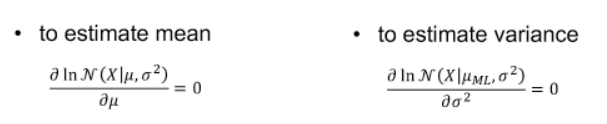
- the mean estimator is unbiased, but the variance estimator is biased
- maximum likelihood estimator is related to overfitting

- histogram as a nonparametric method
- probability of x in a bin

- KDE and kNN
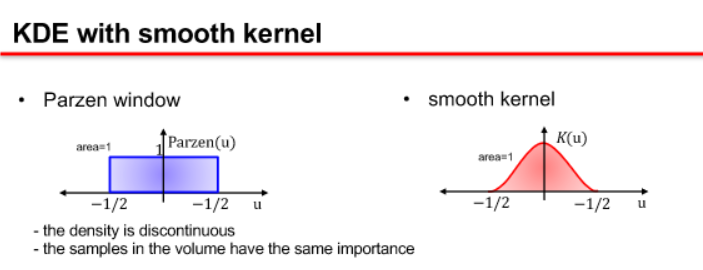
- kernel density estimation (KDE)
- k nearest neighbors (kNN)
- fix k, and increase V to include k samples
- kernel density estimation (KDE)
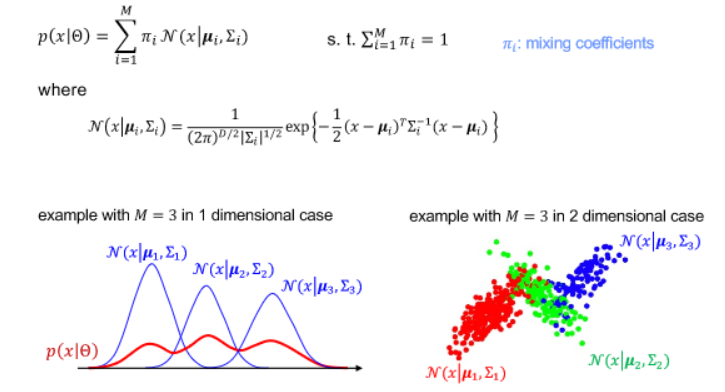
- Semi-parametric method
- Mixture of Gaussian